커피 컬럼 정보
좋은 커피와 맛있는 커피 ― 한국인이 선호하는 커피 맛의 10가지 유형
2017-02-02









| 원문출처 | http://blog.naver.com/lussolab/220940190062 |
|---|

좋은 커피와 맛있는 커피
한국인이 선호하는 커피 맛의 10가지 유형
한 잔의 커피가 고객에게 전달되기 위해서는 여러 단계를 거쳐야 합니다. 산지에서 농부가 정성스럽게 수확한 생두는 가공이 되고 유통 과정을 거쳐 로스팅 회사로 들어오게 되죠. 그리고 로스팅 회사나 로스터리 카페는 생두의 맛을 잘 살릴 수 있도록 로스팅 한 후 음료로 만들어 고객에게 전달하고 있습니다. 고객에게 맛있는 커피를 전달하기 위해서 각 단계별로 많은 커피 종사자들이 노력을 기울이고 있습니다.
그런데 어느 순간 ‘맛있는 커피는 무엇일까?’ 라는 의문에 빠졌습니다. 맛있는 커피에 대해 물어보면 대부분 생산지나 품종, 숙련된 바리스타와 추출 등 좋은 커피를 이야기 했습니다. 그러다 커피가 아닌 ‘맛있다’라는 것 자체로 물음이 옮겨 갔습니다.
초콜릿, 아이스크림, 케이크, 스테이크, 치킨 등등 모두 맛있는 음식입니다. 그럼 홍어, 두리안, 취두부, 블루치즈 같은 음식은 어떤가요? 누군가 에게는 맛있는 음식이고, 또 누군가는 가까이 하기도 힘든 음식입니다.

도대체 맛있다라는 것은 무엇일까요?
저는 맛은 크게 두 가지로 나뉜다고 생각합니다. 본능적으로 좋아하는 맛과 문화적인 유전자에 의해 좋아하게 되는 맛, 즉 맛에도 DNA와 MEME이 있는 것이죠. EBS에서 진행한 ‘아이의 식생활’이라는 실험을 보면 아주 흥미롭습니다. 50일 된 아기에게 단맛, 쓴맛, 신맛을 보여주고 반응을 확인한 것인데, 단맛에는 아기가 바로 웃는 반면 쓴 맛과 신맛에서는 얼굴을 찌푸렸습니다. 이는 우리나라를 비롯해 일본, 미국 모두 동일한 단맛을 주면 웃는 반면 쓴 맛과 신 맛에는 얼굴을 찌푸리는 것을 볼 수 있습니다. 단맛은 생존을 위한 본능적인 맛으로, 쓴맛과 신맛은 문화적으로 교육된 맛이 아닌가라는 생각이 드는 대목이었습니다.

읽어봄직한 연관글 : 커피의 맛에서 「신맛」은 무엇입니까?
다시 커피로 돌아오면 ‘좋은 커피’에 대한 기준은 상당히 체계적이고 명확합니다. 또 SCAA의 아로마 휠에 있는 플레이버 노트와 에프터테이스트, 산미, 바디, 밸런스의 강도, 단맛 여부 등을 고려해보면 해당 조합은 대략 153,092,096종의 커피가 나올 수 있는 조건이 됩니다. 이 조합 중 총 점수가 80점을 넘으면 모두 맛있는 커피라고 할 수 있을까요? 우리가 맛있는 커피를 재차 강조하는 이유는 고객 원하는 커피가 좋은 커피이기도 하지만 맛있는 커피이기 때문입니다.
사람들이 좋아하는 차량의 색상, 디자인은 다를 수 있지만 연비가 좋은 차를 싫어하는 사람은 없습니다. 커피에도 맛있다고 느끼게 하는 핵심요소가 있을지, 사람들이 선호하는 커피에서 동일하게 나오는 요소가 있는지 우리는 먼저 맛있는 커피에 대한 모습을 구체화 하는 작업을 시작했습니다.
첫번째 시도로 1000명의 소비자들에게 5가지 커피 샘플을 주고, 커피 맛을 평가하게 한 후 최종적으로 한가지를 선택하게 했습니다. 결론은 ‘우리가 뭘 한 거지?’ 였습니다. 같은 커피임에도 불구하고 주관적으로 맛을 표현했고, 이것의 평균을 내면 대부분의 커피가 3-4점 사이로 수렴됩니다. 데이터가 많아지면 많아질수록 커피들은 비슷한 모습으로 표현되었습니다. 결국 고객들은 맛있는 커피를 선택할 수 있으나, 본인이 왜 맛있다고 느끼는지 설명할 수 없다는 것을 깨달았습니다.
1단계 분석
고객이 맛있어 하는 커피는 어떤 모습일까?
5가지의 샘플을 소비자에게 비교 테스트 진행 (customer survey : 5 Samples)
→ 6개의 요소는 객관식 (5점 척도)으로 구성
→ 향에 대해서는 주관식으로 질문
→ 최종적으로 “다시 마시고 싶습니까?”라는 질문으로 마무리, 객관식 (5점 척도)
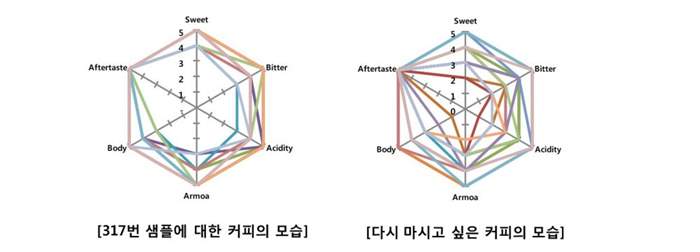
자료1. (좌) 동일한 커피임에도 커피에 대한 평가가 다르며 / (우) 스파이더그램의 점수를 평균 내면 대부분 3~4점으로 수렴된다
1단계 분석에서 우리가 얻은 결론
-도대체 어떤 커피가 맛있는 거지? (So what?)
- 고객에게 어렵게 물어보지 말 것 (Don’t ask the customer with difficulty)
하지만 이 데이터를 통해 의미 있는 결과를 한가지 발견했습니다. 다시 마시고 싶은 커피의 주요 요소가 쓴맛과 애프터 테이스트라는 것 입니다. 쓴 맛은 강할수록 부정적인 방향으로 애프터 테이스트는 강할수록 긍정적인 방향으로 나왔습니다.
다시 먹어 보고 싶은 커피를 Y (종속변수)로 커피의 맛과 향 등을 X (독립변수)로 두고
(1) 샘플 5개 / 대상자 1,000명
(2) 1차적으로 가능한 모든 변수들 간의 상관 분석을 진행 (강도는 5점 척도, 향 유무는 더미 처리)
- 처음 조사된 39개의 독립변수들 중 유사성을 가진 변수를 정리하여 6가지 변수로 필더링 작업 진행
(3) 6가지 변수로 축약 후 2차적으로 다중 회귀분석을 진행
※ 「상관 분석」이란 변수간의 상관 계수에 대하여 추정과 검증을 하는 것. 변수 상호간의 관계가 있느냐 없느냐를 묻지만 무엇이 독립변수이고 종속변수 인지는 모름.
※ 「회귀 분석」이란 종속변수와 독립변수 사이의 최적 선형 함수관계를 밝히는 통계적 기법. 독립변수와 종속변수가 분리 됨으로 인하여 모델링이 가능함.
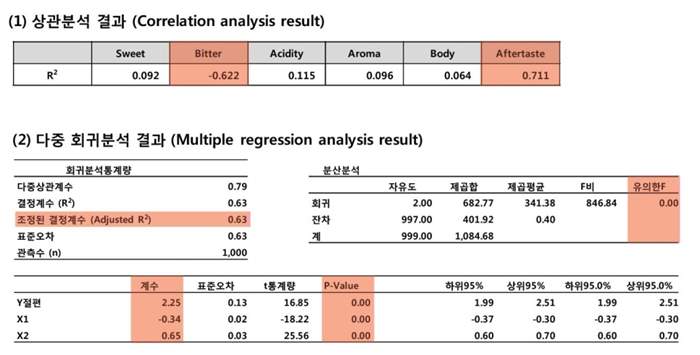
자료2. 1단계 분석의 데이터를 위와 같이 재 세팅하고 모든 독립변수의 상관분석을 진행했다. 유사성을 가지는 변수들을 정리하여 6가지 변수로 필터링 작업을 진행, 그 후 6개의 독립변수와 1개의 종속변수를 정의하고 2차적으로 다중회귀분석을 했다.
당시엔 이 결과를 보고 에프터테이스트와 쓴맛의 변수로 어느 정도 커피의 맛을 찾았다고 생각했으나, 결국 이 것도 수백, 수 천 가지 조합이 존재하기 때문에 맛있는 커피의 모습을 구체적으로 그리기에 적합한 방법이 아니었습니다.
그리고 시각을 바꿔 고객이 선호한다고 대답한 커피 샘플을 수거해 전문가들을 통해 해당 제품의 관능을 해체하기로 했습니다. 또 상관분석이나 회귀분석이 아니라 커피의 맛을 유형화할 수 있는 다른 통계학적 방법을 검토 했습니다. 그렇게 반복되고 지루한 작업의 연속인 두번째 시도가 시작 되었습니다.
2단계 분석
앞서 깨달은 대로 맛있는 커피를 모아 특정 요소를 뽑아내는 것이 아니라 고객들이 맛있다고 생각하는 커피를 분류했습니다. 통계학적으로 분류가 되면 그것들을 다시 트라이앵귤레이션을 통해 분류된 것들이 같은 분류에서는 다른 뉘앙스로 다른 분류에서는 다른 뉘앙스인지 테스트하기로 계획을 세우고 맛에 대한 특정요소(예를 들면 ‘로부스타향’)에 가중치를 반영하여 재 작업하는 과정을 반복하여 진행했습니다.
이를 위해 소비자 조사를 통해 고객이 선호하는 제품을 리스트화 했습니다. 총 26개의 블렌드로해당 샘플을 수거해 루소 연구개발실에 관능검사를 의뢰했습니다. 그리고 데이터 탐색 툴을 활용하여 가설을 세운 후 분류분석과 K-means라는 방법을 사용하여 맛있는 커피의 유형을 분류하기로 했습니다. 그 후 관능 검사로 나온 결과를 1차로 계층적 분류 분석을 진행했습니다. 제품들이 통계적 거리가 가까운 순서로 분류는 잘되었지만 분류된 그룹들끼리 관능을 통해 다시 검증하면 잘 맞지 않았습니다. 같은 그룹 내에서 다른 뉘앙스가 있기도 하고, 다른 그룹 간에 같은 뉘앙스가 있기도 했습니다.
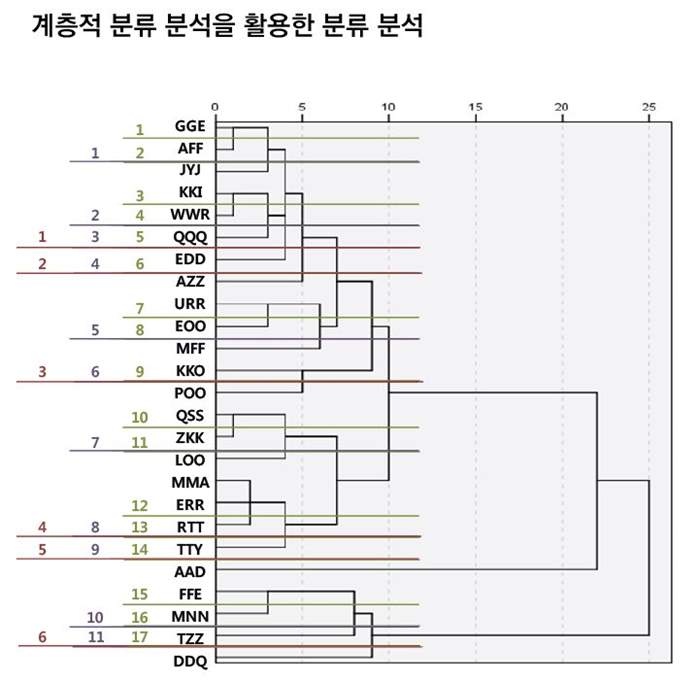
그래서 K-means 클러스터링이라는 방법을 통해 재 분류해보았습니다. 계층적 분류분석을 각각 제품들 간에 통계학적으로 가까운 순서들끼리 묶는 방법이라고 하면, K-means 클러스터링은 비약적으로 발전된 컴퓨터 능력을 가지고 우리가 정한 K를 묶어내는 방법입니다. K를 15개로 시작해서 한 단계씩 줄였습니다. 또 ‘의미 있는 분석이 되기 위해 데이터가 적은 것이 아닐까’하는 우려를 없애기 위해 분류에 영향을 주지 않는 더미들(저희는 위성데이터라고 표현했습니다), 특정 제품이 발현한 값에서 다른 제품에 영향을 미치지 않을 정도의 미세한 위성 데이터들을 만들어 분류했습니다.
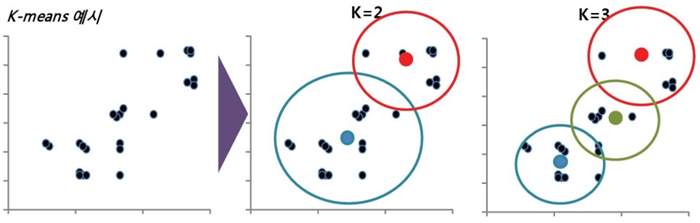
자료3. K-means Clustering을 활용하여 분류 분석 진행: 통계프로그램을 활용하여 K를 15→14→13→12→11→10→9→8→7 등으로 진행 각 클러스터의 센트로이드간의 거리와 클러스터별 센트로이드에서의Inner Distance를 측정하여 가장 효율적인 K를 선택 (10개)
Tip. K-Means 분류방법 특성상 분류하려는 차원을 이루는 요소보다 데이터 집합이 더 많아야 함으로 거리에 영향을 주지 않을 데이터를 Dummy로 생성하여 해당 작업을 진행
통계적으로 분류하고 다시 관능 검사를 통해 같은 클러스터끼리 동일한 뉘앙스인지 다른 클러스터와 다른 뉘앙스인지 여러 차례 재검사를 통해 검증한 결과 마침내 맛있는 커피의 모습을 알아냈습니다.
"소비자 조사에서 선정된 26개의 샘플을
총 10개의 맛 유형(클러스터)로 분류"
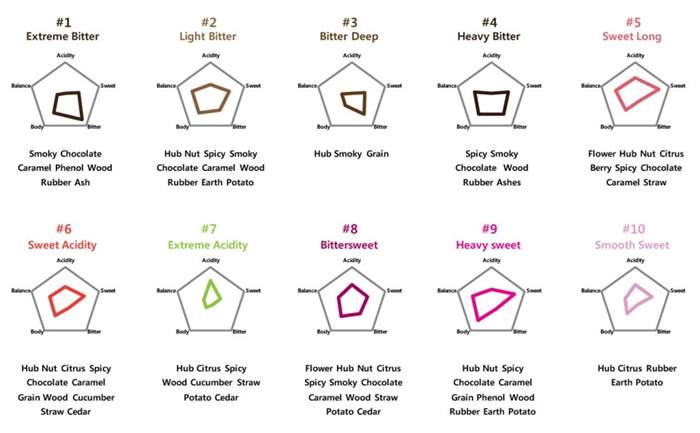
자료4. 총 10가지로 분류된 한국인이 선호하는 커피 맛의 유형 - 스파이더 그램
고객들이 선호하는 한국의 블렌드 26개의 제품은 총 10개의 클러스터로 분류되었습니다. 예를 들면 클러스터 1번은 스모키하고 초콜릿하며 쓴맛이 극단적으로 강조된 모습이고, 10번은 부드러우면서 단맛이 강하며 시트러스한 커피 입니다.
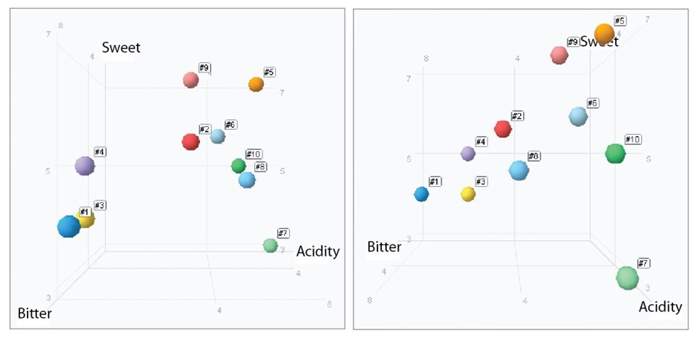
자료5. 위 자료 4의 스파이더그램(2차원)을 3차원으로 구현한 것. 좌/우의 표는 동일한 클러스터로 보는 각도에 따라 맛의 요소 간의 거리가 달라진다.
위 10가지 맛의 유형이 우리가 1년 이상 연구한 한국인이 좋아하는 맛있는 커피의 모습입니다. 이는 제게 매우 의미 있는 작업이었고 이 작업이 계속 진행된다면 언젠가는 옷 사이즈를 고르듯 원하는 커피 맛을 선택할 수 있게 될지도 모른다는 기대감이 생겼습니다.

마릴린 (7967) 외 앤디워홀 작품들
이 프로젝트를 시작한 동기는 고객들에게 보다 맛있는 커피를 쉽게 대접하기 위해서였습니다. 하지만 문득 이런 반문을 하게 되었습니다. 2016 COE 옥션 결과를 보면 상위에 게이샤 품종이 압도적입니다. 분명 좋은 품종입니다만, 한 가지 방향으로 통일되는 것이 과연 좋은 것인가 하는 것입니다. 또 최근 커피 전문가라고 하는 사람들이 추천하는 커피의 유형이 한 방향으로 흘러가고 있는 것은 아닌지, ‘이게 우리가 정의한 좋은 커피이니 맛있는 커피 입니다.’라고 강요하고 있는 것은 아닌지 하는 것 입니다.
좋은 커피를 만들어 내기 위한 커피 종사자들의 노력도 중요하지만 좋은 커피를 즐기는 고객도 중요합니다. 그리고 이러한 재미있는 일들이 지속되려면 커피의 다양성이 확보되어야 한다고 생각했습니다.
커피를 사랑하는 고객들에게, 커피산업에 종사하는 사람들을 위해 그리고 커피를 위해 맛있는 커피라는 화두를 여러분들에게 드리고자 합니다. 우리는 보다 맛있는 커피, 좋은 커피, 그리고 다양한 커피에 대한 고민을 함께하고 싶습니다.
읽어봄직한 연관글 : 커피의 쓴맛은 어떻게 생기는가?⑴
| 정현용 Director, CK Corporations |

루소 커피의 부장. 기업에 필요한 데이터 분석 능력과 숫자 감각이 뛰어나다.
분석적인 시각으로 커피 맛에 접근, 2016 월드 커피 리더스 포럼을 통해 한국형 커피 맛의 규격에 대한 첫번째 분석 결과를 발제 했다. 회사 밖에서는 사자처럼 거대한 고양이 모시는 집사로 의외성을 가지고 있다.

ABOUT ME





일상 커피의 조건(ft.중국의 저가 커피 브랜드 루이싱 커피... 2
일상 커피의 조건(ft.중국의 저가 커피 브랜드 루이싱 커피의 실패와 성공) by 노띵 커피 원문 : 일상 커피의 조건 〔프롤로그〕 품질이 좋은 커피를 선택할 가장 간단하고 명확한 방법은 '가격'입니다. 고품질의 커...
등록일: 2024-02-21
스페셜티 커피와 다크 로스트 ― 굳이 스페셜티 커피를 다크... 2
스페셜티 커피와 다크 로스트 ― 굳이 스페셜티 커피를 다크 로스팅으로 그럼에도 우리는 커피를 블렌딩하지 않습니다. by 노띵커피 그럼에도 우리는 커피를 블렌딩하지 않습니다.작성자 : 노띵커피이 컨텐츠는 블렌드...
등록일: 2024-01-30
커피를 분쇄하기 전, 물을 꼭 뿌려야 할까? 커피를 분쇄하기 전, 물을 뿌려야 하는 이유 ― 크리스토퍼 헨든의 새로운 논문 관련 기사 관련하여 호주의 바리스타 교육 사이트로 유명한 바리스타 허슬에서 관련 포스트...
등록일: 2024-01-10
커피 그라인딩(Grind) ― 에스프레소 분쇄 입도 분포에서 쌍...
Grind ― 에스프레소 분쇄 입도 분포에서 쌍봉 이상의 분포(Multimodal)가 필요한 이유 커피 분쇄에서 입도 분포라는 용어는 원두를 분쇄했을 때, 원두 입자의 크기별 분포도를 가리키는 것입니다. 흔히 상업용 에스프...
등록일: 2023-12-27
커피 그라인더의 발열 제어가 중요한 이유(The Cold Grind ...
커피 그라인더의 발열 제어가 중요한 이유(The Cold Grind Uprising) The Cold Grind Uprising — Coffee Technicians Guild Undoubtedly, a high degree of obsession is required for engineering better coffee... ...
등록일: 2023-12-19
커피를 분쇄하기 전, 물을 뿌려야 하는 이유 ― 크리스토퍼 ... 4
커피를 분쇄하기 전, 물을 뿌려야 하는 이유 ― 크리스토퍼 헨든의 새로운 논문 관련 화학자이자 스페셜티 커피씬에서 "물"과 분쇄 입자 크기의 중요성에 대한 논문으로 지대한 영향을 미쳤던 크리스토퍼 헨든의 새로...
등록일: 2023-12-07
보편적 로스팅 이론에 갇히지 않았던 것이 우승 비결, IKRC...
보편적 로스팅 이론에 갇히지 않았던 것이 우승 비결, IKRC 우승자 유종규 인터뷰 올해로 4회차를 맞이한 2023 이카와 코리아 로스팅 챔피언십 (IKRC)에서 우승한 로익스커피 소속의 유종규 로스터를 만나봤습니다. ...
등록일: 2023-11-28
커피 로스팅 팩토리에서 하이엔드 1그룹 에스프레소 머신이...
커피 로스팅 팩토리에서 하이엔드 1그룹 에스프레소 머신이 필요한 이유 위 영상에서는 호주의 유명 로스터리이자 세계적인 바리스타들을 보유한 오나(Ona) 커피에서 로스팅 품질 관리를 위해 산레모 YOU를 어떻게 활...
등록일: 2023-11-27
☕️COFFEE 오늘의 팁: ROASTING☕️ 이후 맛의 진화 by Scott Rao
☕️COFFEE 오늘의 팁: ROASTING☕️ 이후 맛의 진화 스캇 라오의 인스타그램 포스트로 시작된 원두의 향미와 화학적 요인들, 그리고 관능에 대한 대화들입니다. 읽다가 내용이 너무 좋아서 번역해서 공유해드립니다. 많...
등록일: 2023-11-02
"로스터라면 결국 쓰시게 될 겁니다" 파이어스코... 1
"로스터라면 결국 쓰시게 될 겁니다" 파이어스코프㈜ 강현준 대표 인터뷰 과거 커피 로스팅 소프트웨어가 부재 했을 당시는 도제식 관행에 따라 반복적 숙달로 관능 훈련하는 것이 오직 좋은 로스터가 되어가는 과정...
등록일: 2023-10-30
7회의 대회도전 그리고 우승, 2023 KBrC 우승자 블랙소울커... 2
7회의 대회도전 그리고 우승 2023 KBrC 우승자 블랙소울커피 김동민 바리스타 인터뷰 2015년 대회를 시작으로 올해까지 브루어스컵 도전 일곱번만에 그가 들어올린 첫 트로피는 우승 트로피였다. 그는 그동안 블랙소...
등록일: 2023-10-20
과학적인 커피 추출 원리를 한데 모은 커피 덕후의 "...
과학적인 커피 추출 원리를 한데 모은 커피 덕후의 "펄사 드리퍼(Pulsar Dripper)" 천체물리학자이자 세계적 커피 덕후인 조나단 간예(Jonathan Gagne)가 제작에 참여한다는 것만으로도 수많은 관심을 얻어왔던 커피 ...
등록일: 2023-10-18
지긋지긋한 그라인더 정전기 해결해 드립니다? - 아카이아 ...
지긋지긋한 그라인더 정전기 해결해 드립니다? - 아카이아 이온빔(Acaia Ion Beam) https://youtu.be/RvELG8E4p2I 특히나 겨울철이 다가오면 커피 애호가들은 지긋지긋한 정전기 문제에 봉착합니다. 그라인더 토출구...
등록일: 2023-10-13
에스프레소 머신으로 30초만에 필터 커피 브루잉 하기, &qu...
에스프레소 머신으로 30초만에 필터 커피 브루잉 하기, "Fast Filter Brew" 최근 들어 Non Bypass Brewing 방식의 접근이 필터 커피 추출에 많이 활용되고 있습니다만, 이러한 Non Bypass 추출의 모티프는 다름 아닌 ...
등록일: 2023-10-10
보다 온전한 에스프레소 한잔을 위한 툴, "Paragon Es...
보다 온전한 에스프레소 한잔을 위한 툴, "Paragon Espresso" Feat. Compound Chilling https://www.youtube.com/watch?v=2f2ugQ-IJ7w 아무리 완벽한 에스프레소라도 추출 이후 샷은 죽어갑니다. 포터필터의 스파웃을...
등록일: 2023-10-05







